Parallelization of a Polarization Image Processing System
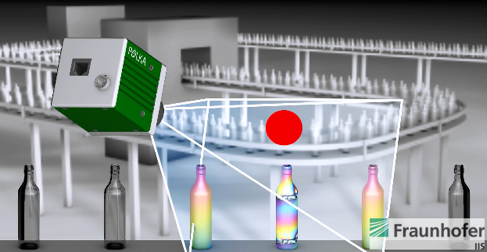
This application is a specialized image processing system for image data originating from a novel polarization image sensor (POLKA) developed at Fraunhofer IIS [7] . This camera is used in industrial inspection, for example in in – line glass [8] and car- bon fiber [9] quality monitoring. Polarization image data is significantly different from ‘traditional’ (i.e. color) image data and requires widely different – and significantly more computation intensive – processing operations as shown in the following workflow:

Challenges
A gain/offset correction is performed on each pixel to equalize sensitivity and linearity inhomogeneity. For this purpose, additional calibration data is required (G/O input in the workflow above).
Since each pixel only provides a part of the polarization in- formation of the incoming photons, the unavailable information is interpolated from the surrounding pixels (similar to Bayer pattern interpolation on color image sen sors). From the interpolated pixel values we now compute the Stokes vector, which is a vector that provides the complete polarization information of each pixel. By appropriate transformations, the Stokes vectors are converted into the degree of linear polarization (DOLP) and angle of linear polarization (AOLP). These parameters are usually the starting point for any further application dependent processing (which is not shown here). For demonstration purposes, we convert AOLP and DOLP into a RGB color image that can be used for visualizing polarization effect.
Polarization image processing is currently used in industrial inspection. For example, inline glass inspection is depicted in the two pictures. Glass products are transported at up to 10 items per second and images are captured. Typically, a single inspection PC will handle multiple cameras and requires at least 20 fps processing capabilities. Currently, for one camera, this rate can be achieved, but in case of multiple camera outputs processed by one PC or in case of different use – cases where the number of output measurement frames increases, it can drop to 6 – 10 fps. This obligates for each use-case to reconsider/investi- gate further optimization possibilities. Our aim is to achieve a minimum of 25 fps as a hard constraint independent of use – case and processing elements in the algorithm chain. This is a hard constraint knowing that without any optimizations and parallelization, we can only achieve around 6 fps.

Solution
The picture on the left shows the POLKA Polarization Camera with glass measurements performed in a single shot per item. Since this is a measurement device, the precision of the measured data is of uttermost importance. Therefore, the standard algorithm is further adapted for each sensor and polarization data is further processed for different use cases. Especially trigonometric computation leads to a large computation overhead.
An alternative based on a number of COTS cam eras is shown in the picture on the right. This system complements the POLKA capabilities with increased spatial resolution and lower system cost. This construction, however, requires a dditional image fusion. The required registration and alignment further increase the compu- tational complexity of the measurement operation [10] .
In both cases, their underlying algorithms need to be adapted to each use case, starting from the Scilab high-level algorithmic description, all the way down to the embedded C / VHDL implementation.
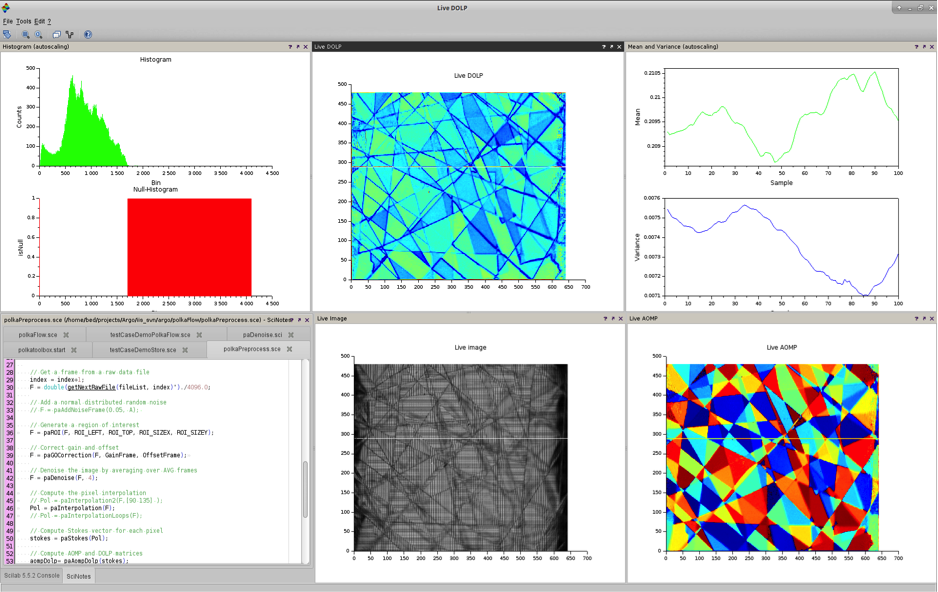
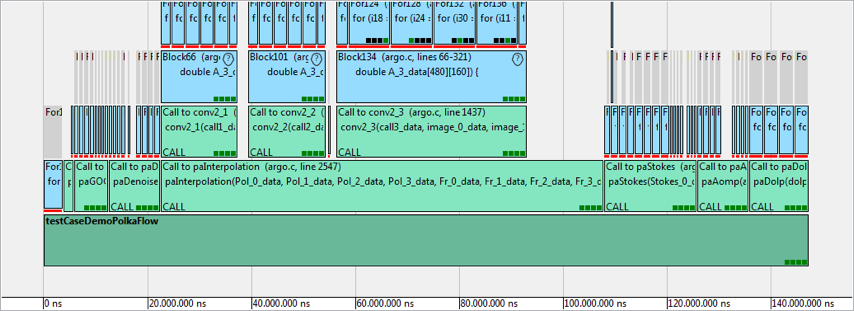
Results
With the complete toolchain starting from the Scilab code and ending up with parallelized C code on heterogeneous embedded systems, the results are:
- Uniform computation over the consecutive steps of the workflow
- Speedup ~3
- No changes in Scilab necessary
- High data locality: data can stay on a single core most of the time

The ARGO Project
The goal of the ARGO (WCET-Aware Parallelization of Model-Based Applications for Heterogeneous Parallel Systems) research project is to develop a toolchain which translates model-based Scilab/Xcos applications into multi-core optimized C code with guaranteed real-time constraints.